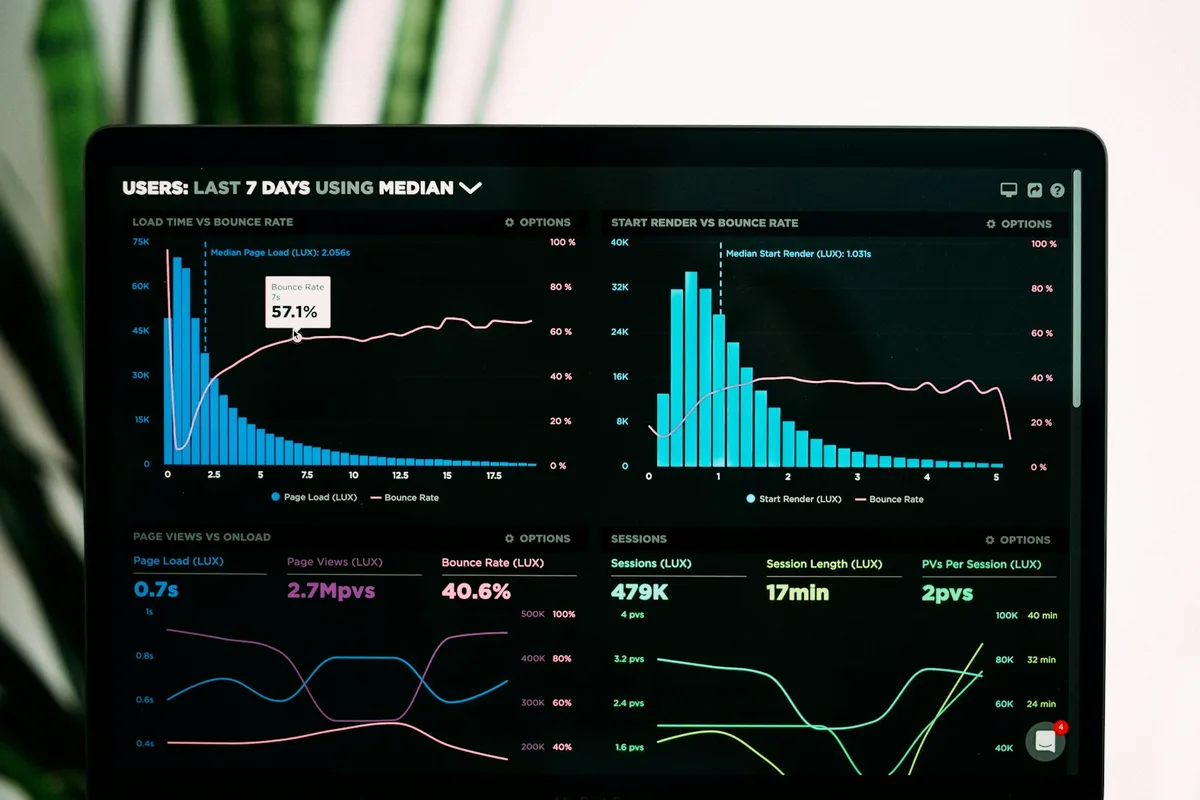
Walk through any troubled EPM programme and the symptoms point the same way: the load failed last night and nobody knows why; actuals don’t reconcile with the ERP; the hierarchy changed and forty modules broke. None of these are modelling problems. They are data problems wearing a planning costume - and they were all visible before the project started.
The anti-pattern: point-to-point heroics
The default integration architecture for a first EPM project is a direct pipe from the ERP (plus three spreadsheets, plus a CRM extract) into the planning platform, built quickly during the implementation by whoever was available. It works on go-live day. It then degrades, silently, because each source change lands directly on the model, and because nobody owns the pipe once the integrator leaves.
What a planning data hub actually is
Not a data warehouse programme. A planning data hub is a thin, owned layer - typically a handful of curated tables on the platform you already have (BigQuery, Snowflake, even a well-run PostgreSQL) - that does four jobs:
- Conform master data once: one product hierarchy, one customer hierarchy, one cost-centre tree, versioned, with effective dates - consumed by every planning model rather than rebuilt inside each.
- Stage transactional feeds at planning granularity, with quality checks that fail loudly before the data reaches the model.
- Hold the integration contract: schemas, refresh windows and SLAs agreed between IT and finance, in writing, so that a source-side change is a negotiation rather than an outage.
- Capture plan outputs back, so that plans, forecasts and actuals can be compared over time without archaeology inside the planning tool.
Why this changes project economics
With a hub in place, the planning platform stops being the place where data problems are discovered and patched. Model logic gets simpler - no defensive formulas around dirty inputs. Adding a second model (workforce after demand, say) costs weeks, not months, because the foundations are already conformed. And when you eventually migrate or add a platform, the hub is what makes the move survivable: the logic is portable because the data layer never belonged to the vendor.
Ownership is the part organisations get wrong
The hub fails if it belongs to “the project”. It needs a named owner - in practice a small data engineering capability with a finance-literate lead - and a budget line that survives go-live. This is usually one to two people, not a department. The test is simple: when the ERP team announces a field change, does someone whose job it is receive that notice and assess the planning impact? If the answer is no, you do not have a data foundation; you have a delay between incidents.
Sequencing for a real programme
- Master data conformance first - it is the highest-leverage, least glamorous work on the critical path.
- Stage the two or three feeds the first model actually needs; resist the urge to boil the lake.
- Write the integration contracts while goodwill is high, not after the first outage.
- Only then let the model build start consuming from the hub.
On programmes shaped this way, we consistently see integration incidents become rare events rather than weekly noise - and, more importantly, planning teams that trust their own numbers. That trust, not the model, is the deliverable.